PS-09 Dictionary
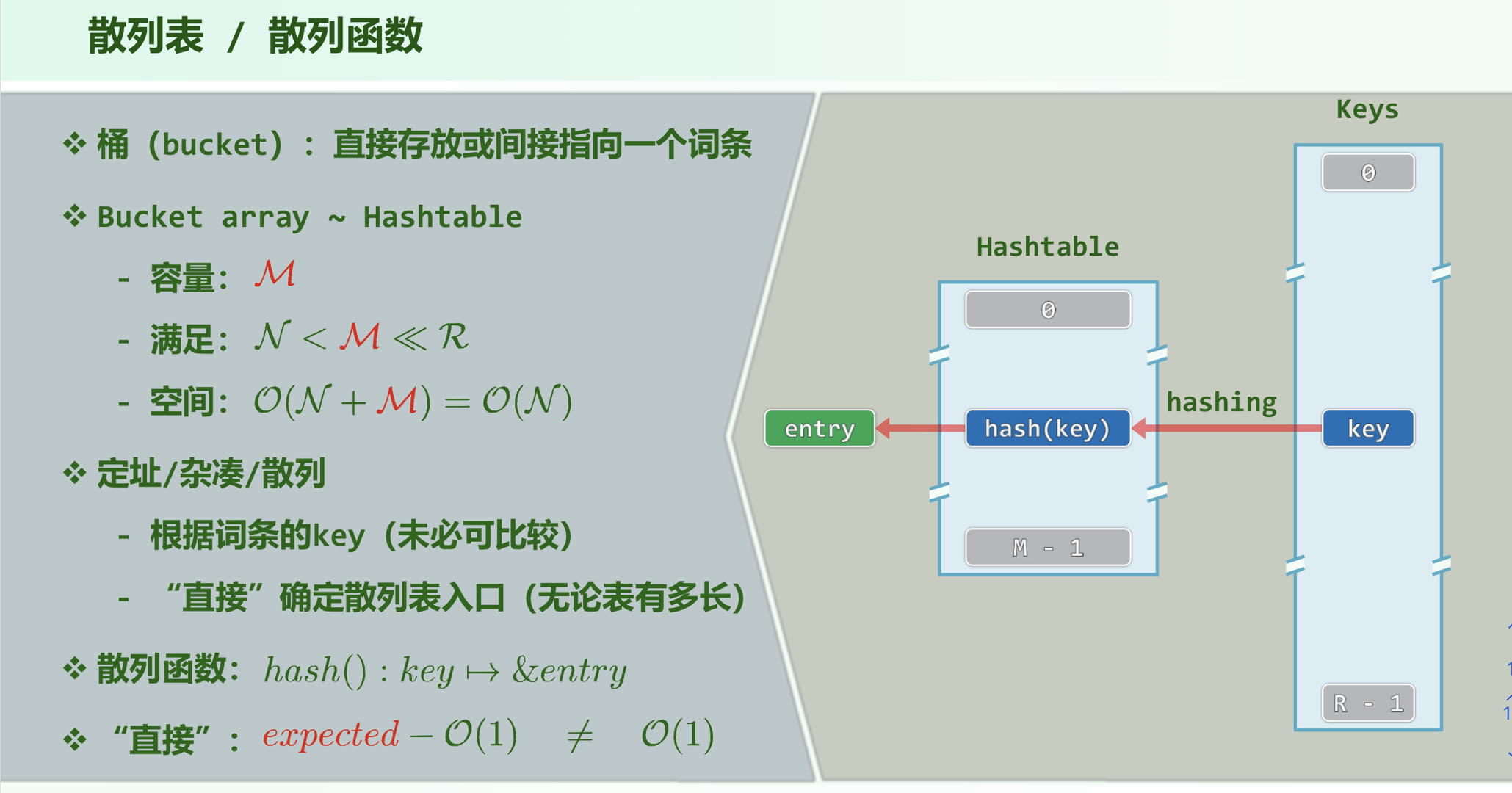
1. 词典
词条的key和value突破了数字的限制
散列:原理
可能存在的key数量很多,但实际存在的key很少,为了节省空间,我们采用散列表
冲突
有可能出现 ,但是 的情况
2. 散列函数
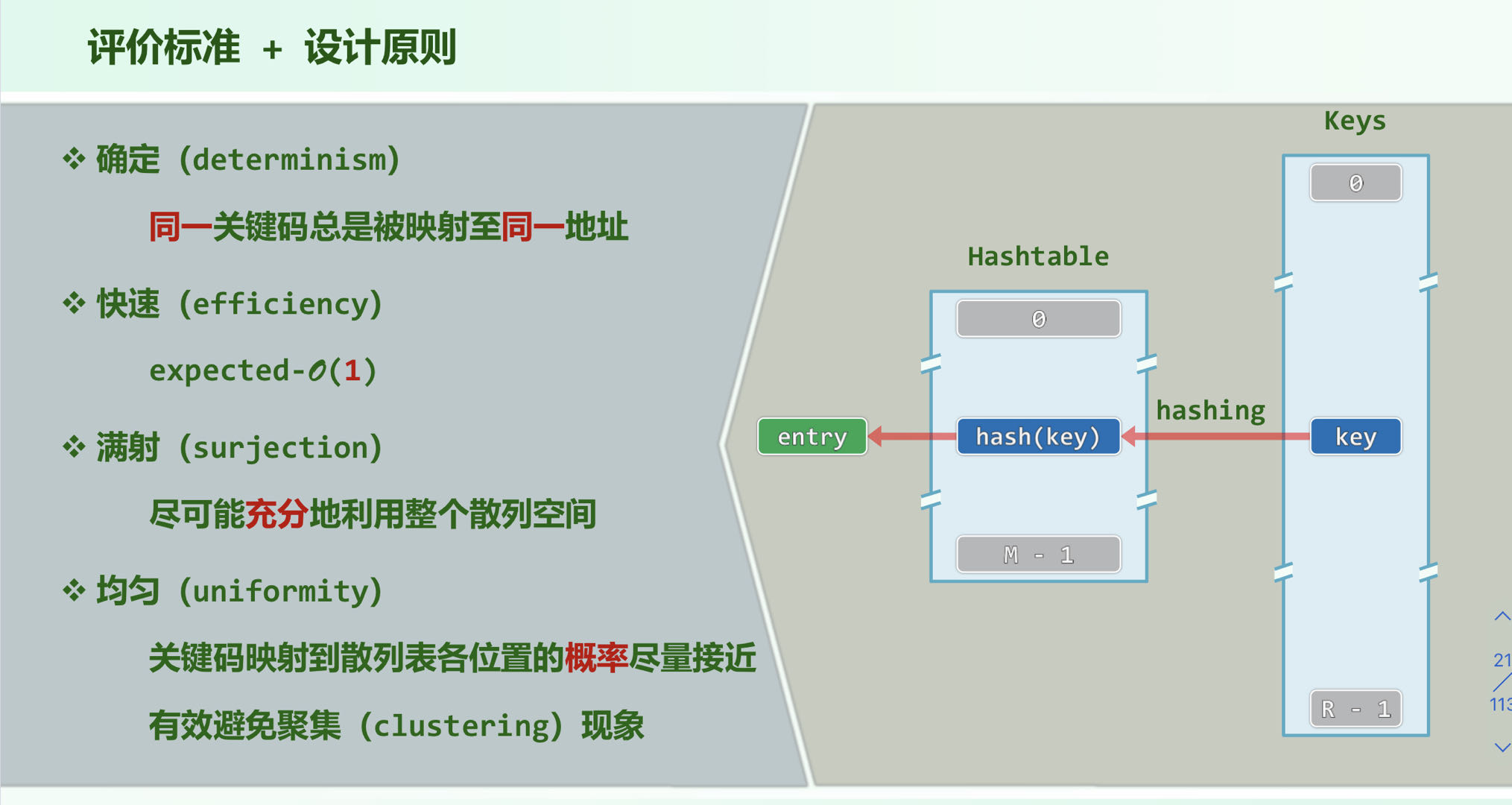
除余法
除余时选取素数,可使数据对散列表的覆盖最充分,分布最均匀
MAD法

散列函数设计的越随机越好
伪随机数法
因各平台随机数生成方法差异很大,该方法可移植性差
3. 排解冲突
开放散列
多槽位
预先将每个bucket细分成几个槽
但是细分程度无法确定,可能不够,也可能空间浪费
公共溢出区
将溢出元素放在额外开辟的区域中,但是一旦溢出就要遍历溢出区
独立链
每个bucket里存入一个链表用以存放冲突,但是指针本身会占用很多空间,调用也很慢
封闭散列
线性试探
从 的对应位置开始试探如果失败则转向下一个桶,直到成功或抵达空桶(失败)
插入:插入到线性试探为空的位置
删除:不能直接删除,因为可能会使线性试探提前中断,要采取懒惰删除的策略
懒惰删除
仅将删除位置做一个标记
当查找时,标记位置看作非空,但是必不匹配
当插入时,标记位置看作空,可以插入元素
重散列
当装填因子过大时,考虑开辟一个更大的散列表,然后将原来散列表的元素集体迁移到新的散列,注意迁移时不可以简单的线性迁移,要回归到hash()之前的key,按照新的散列规则重新计算插入
平方试探
但发生冲突时,可以聪明地跳出冲突区域,减少试探次数
当表长 为素数时,装填因子 ,可以保证散列表正常运行
否则可能会出现在几个元素中反复横跳的情况
双向平方试探
交替地沿两个方向试探
取表长为 ,可以保证试探前 项均互异
4. 桶排序
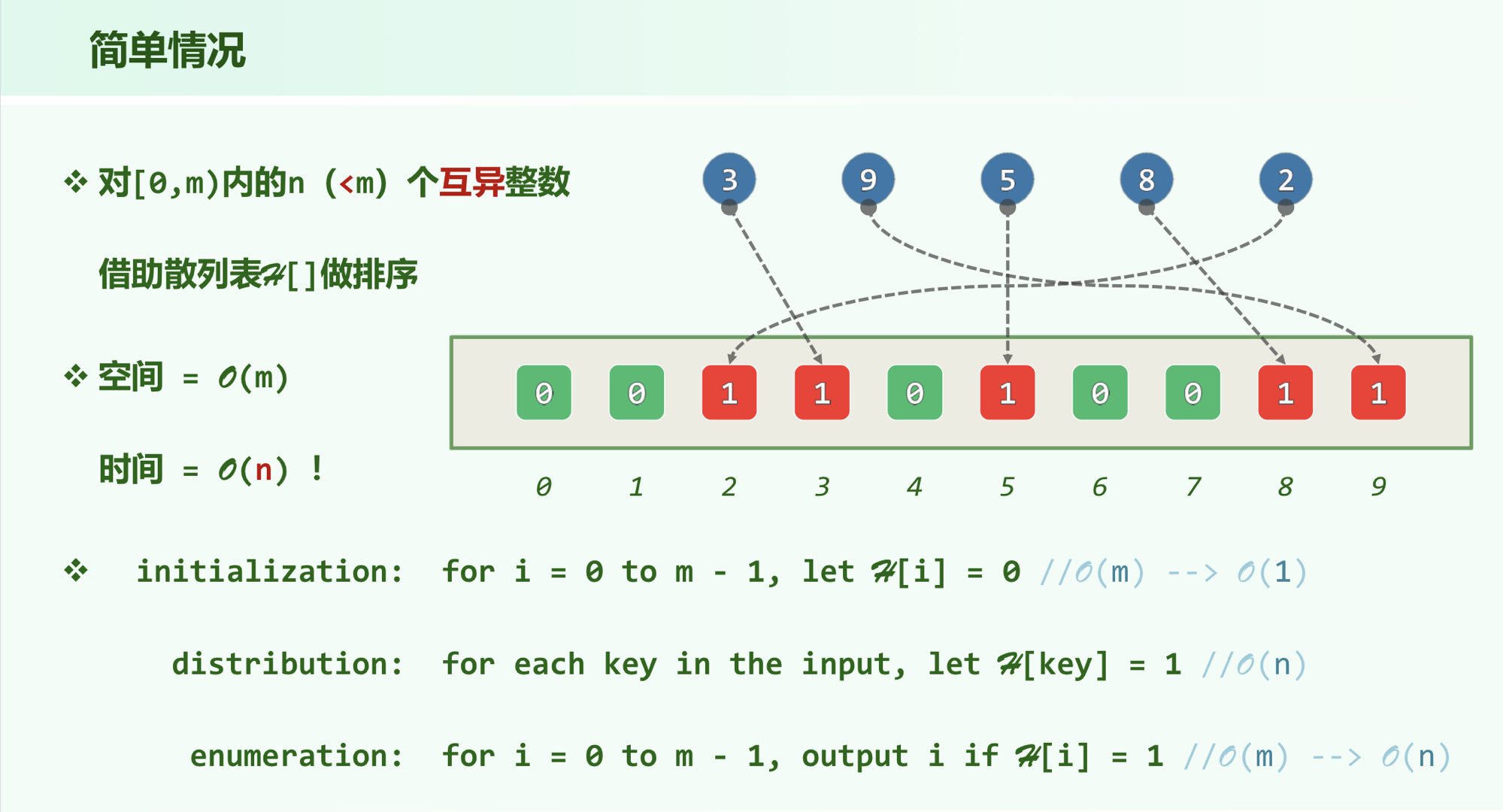
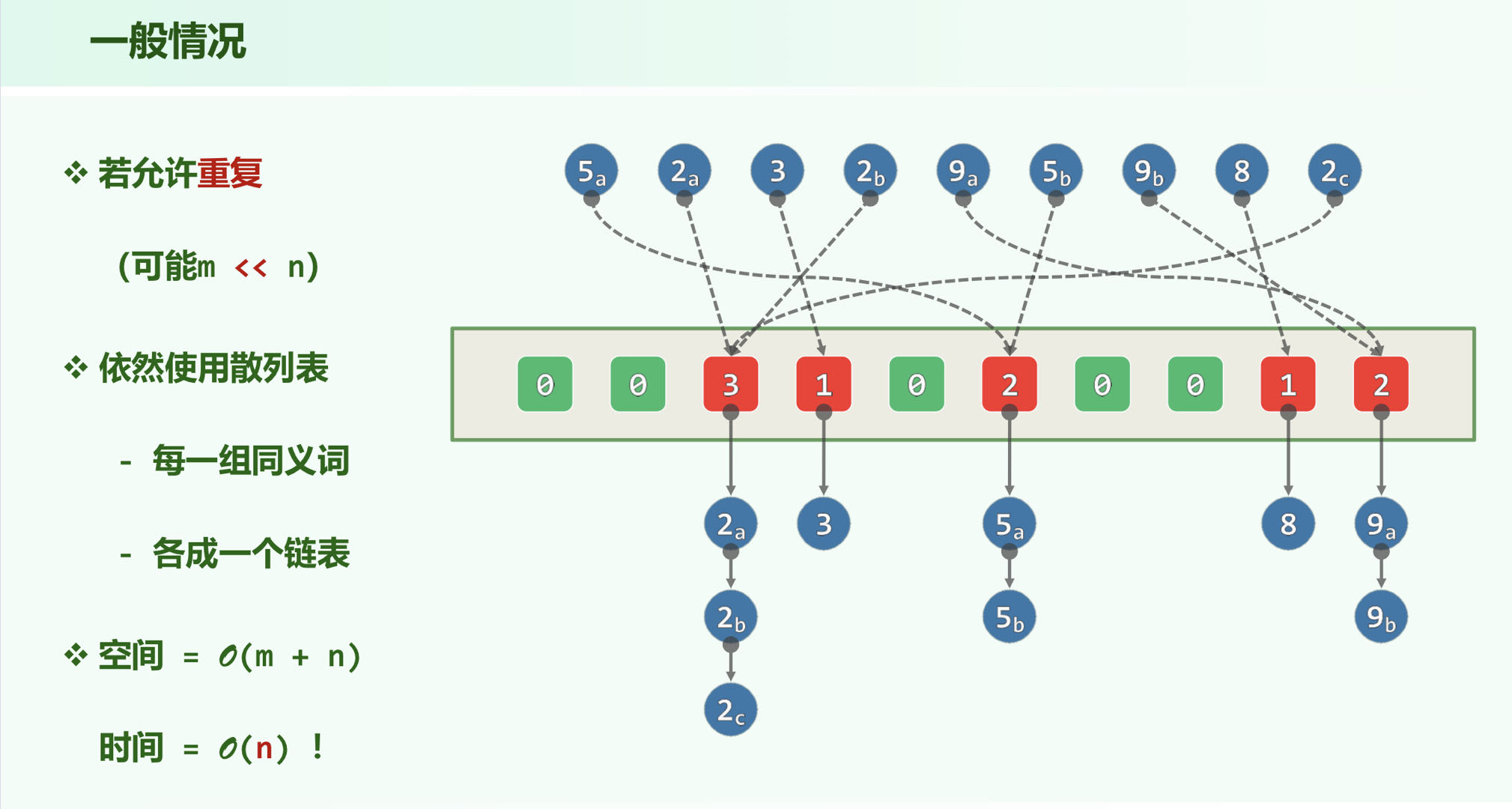
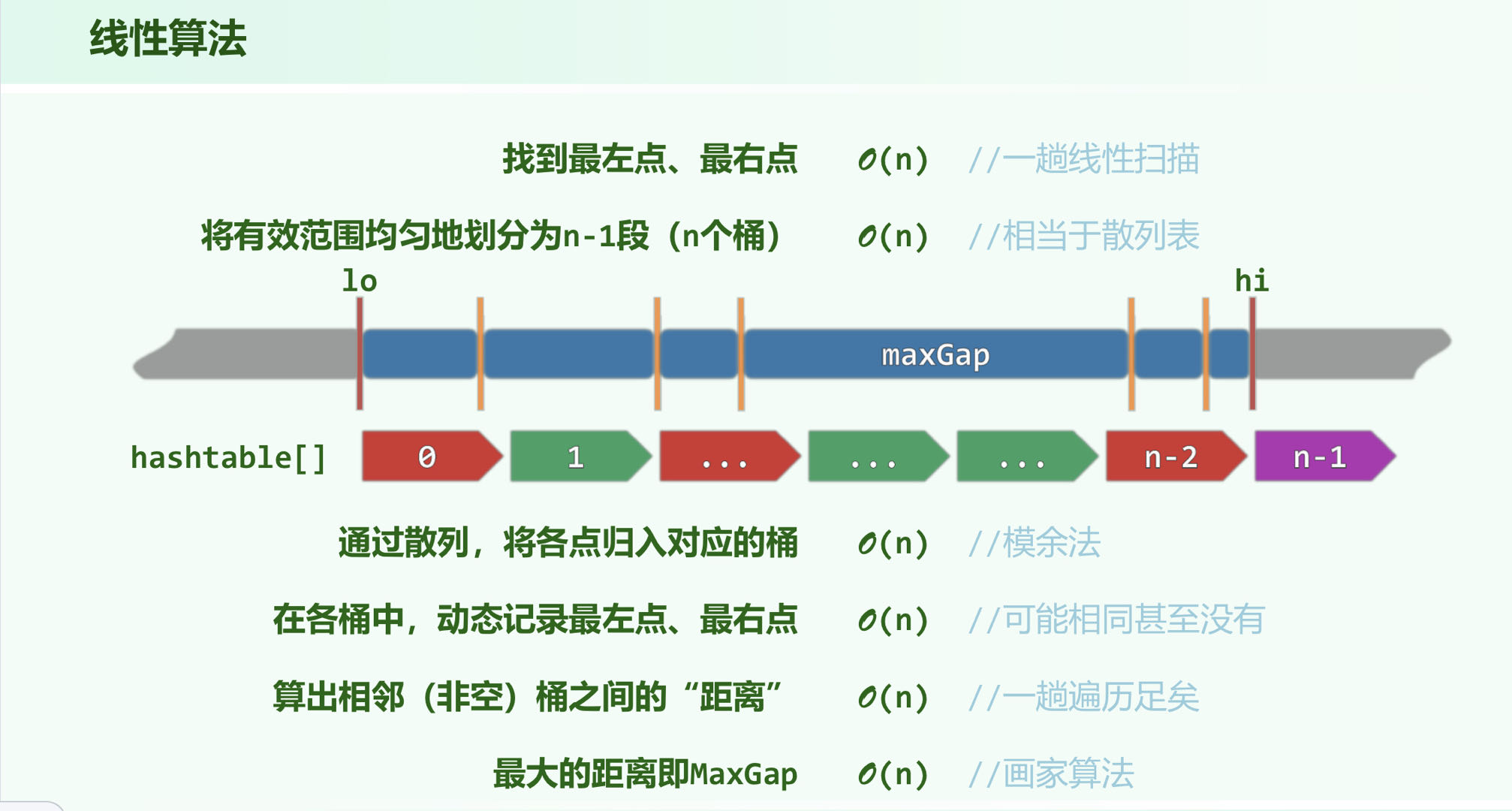
最大缝隙
找出 个点中间隔最大的一段,采用分桶排序,算法复杂度可达
基数排序
关键码由多个域组成
排序时由低位到高位,可保证算法的稳定性
整数排序
每个元素化为 个域,可直接套用基数排序算法
计数排序
“小集合+大数据”类型
按数字大小排序之后,还要按种类排序
经过分桶统计出种类的数量,确定每个种类对应的区间
自后向前扫描,将对应的种类放到尾部,然后计数减一
为什么自后向前?因为分桶的时候最终记的是每个种类最末尾位置的指针
空间复杂度
跳转表
每个元素的塔高期望为2,所以空间复杂度期望为
整体期望塔高为
查找时间复杂度
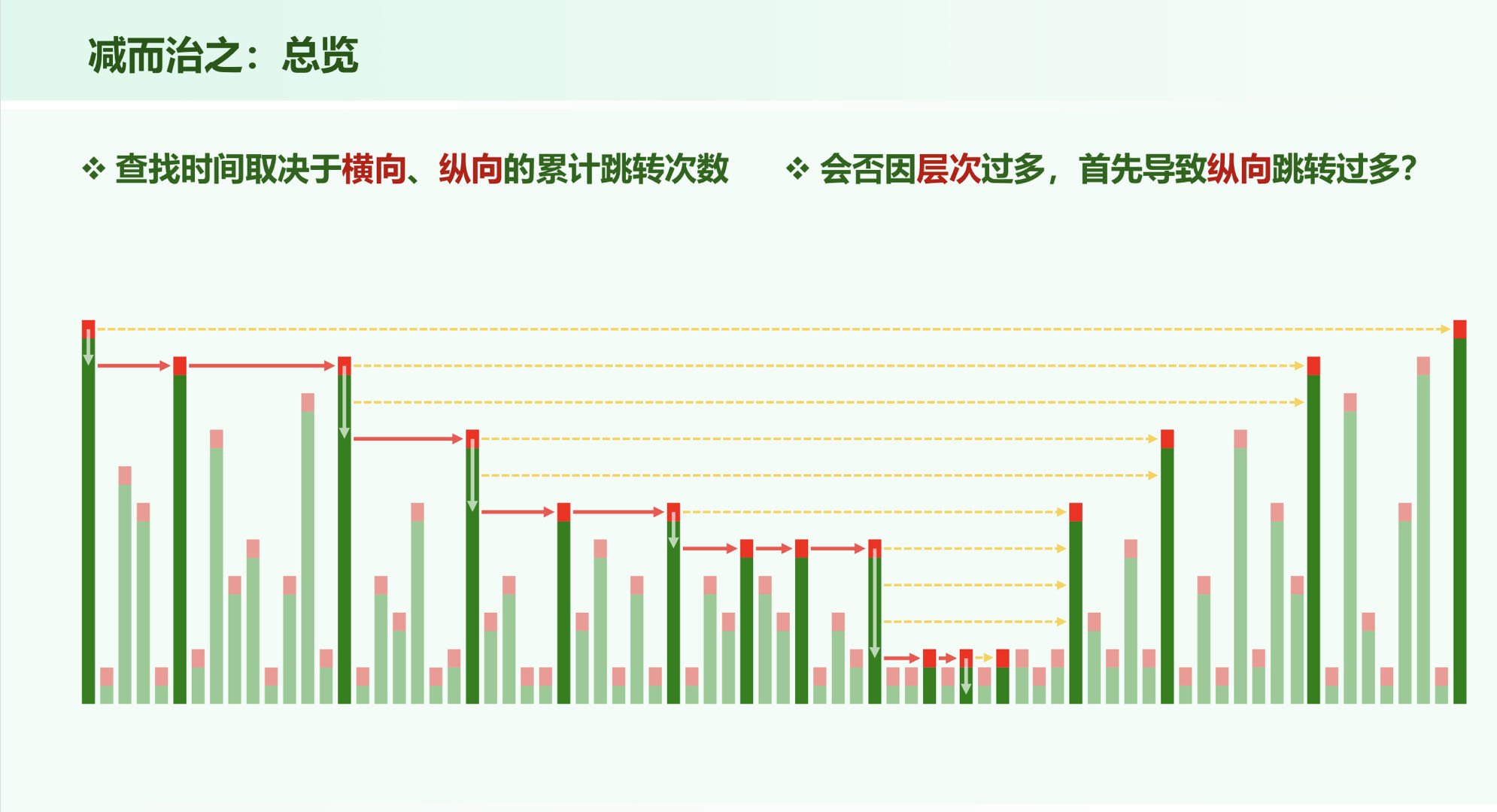
纵向跳转为层高:
横向跳转时,每次都落在塔顶上,每层的塔顶期望的只有2个,因此也为